通过Azure API管理服务(APIM)解决Azure OpenAI Token限制问题
一句话概述
通过Azure的API Management(APIM)服务实现后端多个Azure OpenAI资源的负载均衡,以有效解决Azure OpenAI的TPM配额限制问题,提升系统性能和可用性。
一、面临的挑战
与任何服务一样,Azure OpenAI 也有服务配额和限制,具体取决于您使用的模型。当您的场景所需令牌数远远超过限制,只使用一个区域endpoint可能就无法满足要求。要么程序员在应用开发时将提示词字符串最小化,例如降低前后文关联,要么通过负载均衡来解决令牌限制问题。
二、方案概述
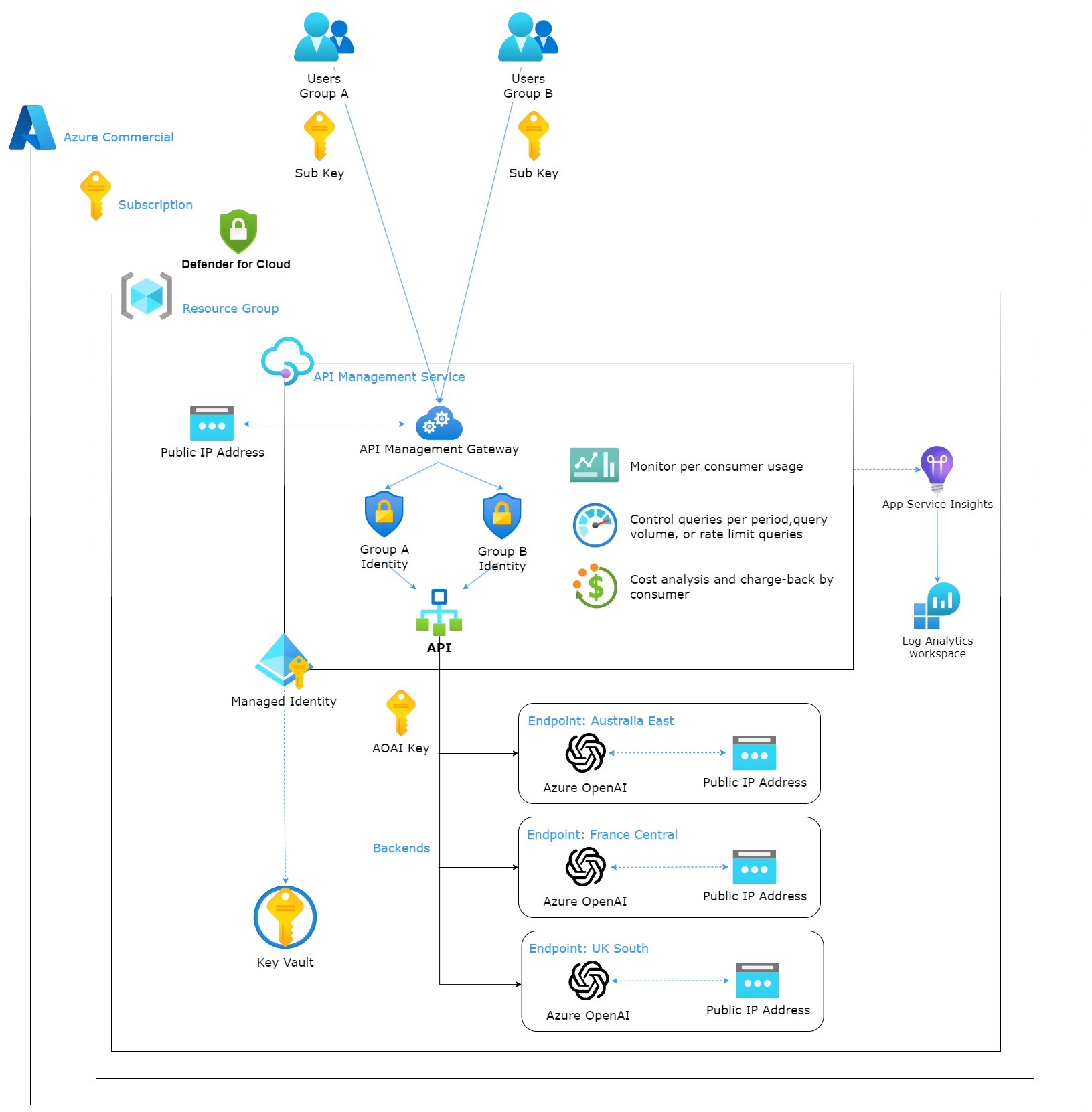
为了解决Azure OpenAI令牌限制,本方案通过Azure API管理服务(简称APIM)来实现负载均衡,跨区域管理多个不同的后端Azure OpenAI实例,从而达到解决令牌限制的目的。使用APIM,API的安全性提高了,因为开发人员只需要记住APIM提供的密钥和URL地址,而不需要使用后端Azure OpenAI实例的密钥和终结点信息。另外,APIM也提供监控功能,可以监控API的使用情况。
三、方案架构
四、方案实操
下面是我如何配置APIM以在三个Azure OpenAI资源之间进行负载平衡的示例。
1、创建API管理服务(APIM)
在Microsoft Azure控制台中搜索“API管理服务”,然后创建一个API管理服务。
创建APIM时的相关信息根据实际情况填写即可。
一直点击“下一步”直到最后“创建”,等待资源部署完成。
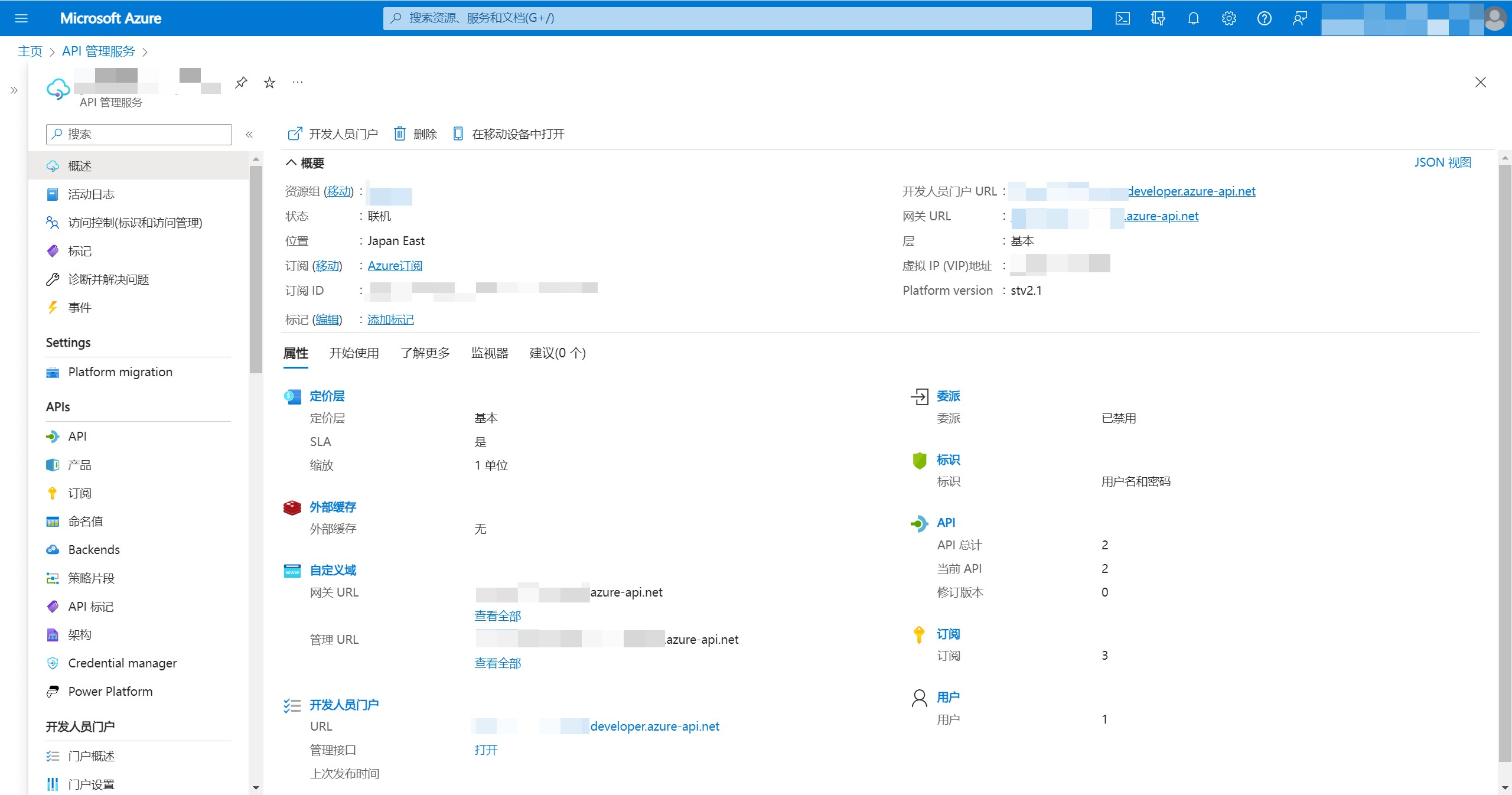
APIM部署完成后,状态为“联机”,获取网关URL(结尾为azure-api.net),应用调用Azure OpenAI将使用网关URL,而不是每个区域的endpoint地址。
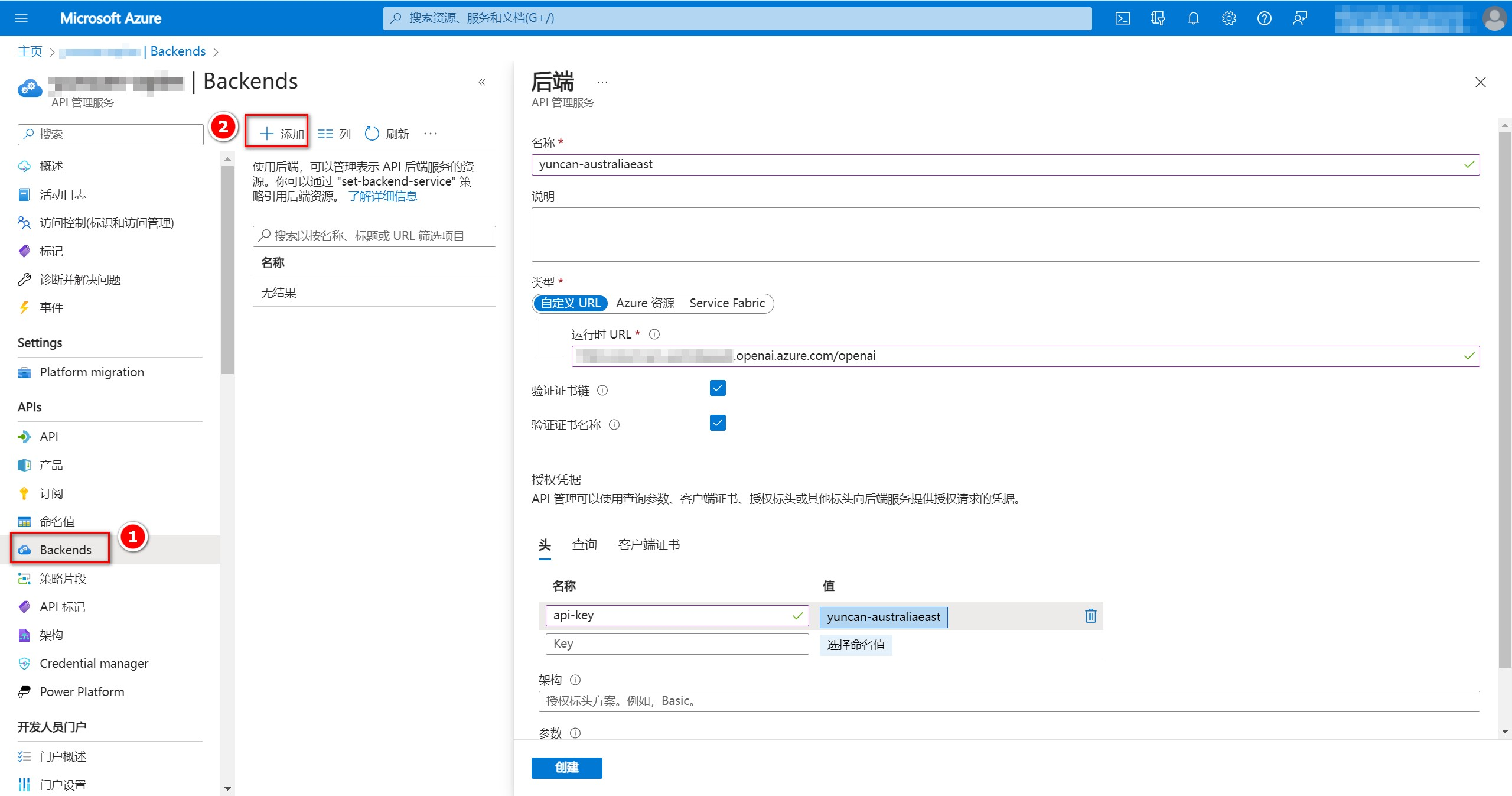
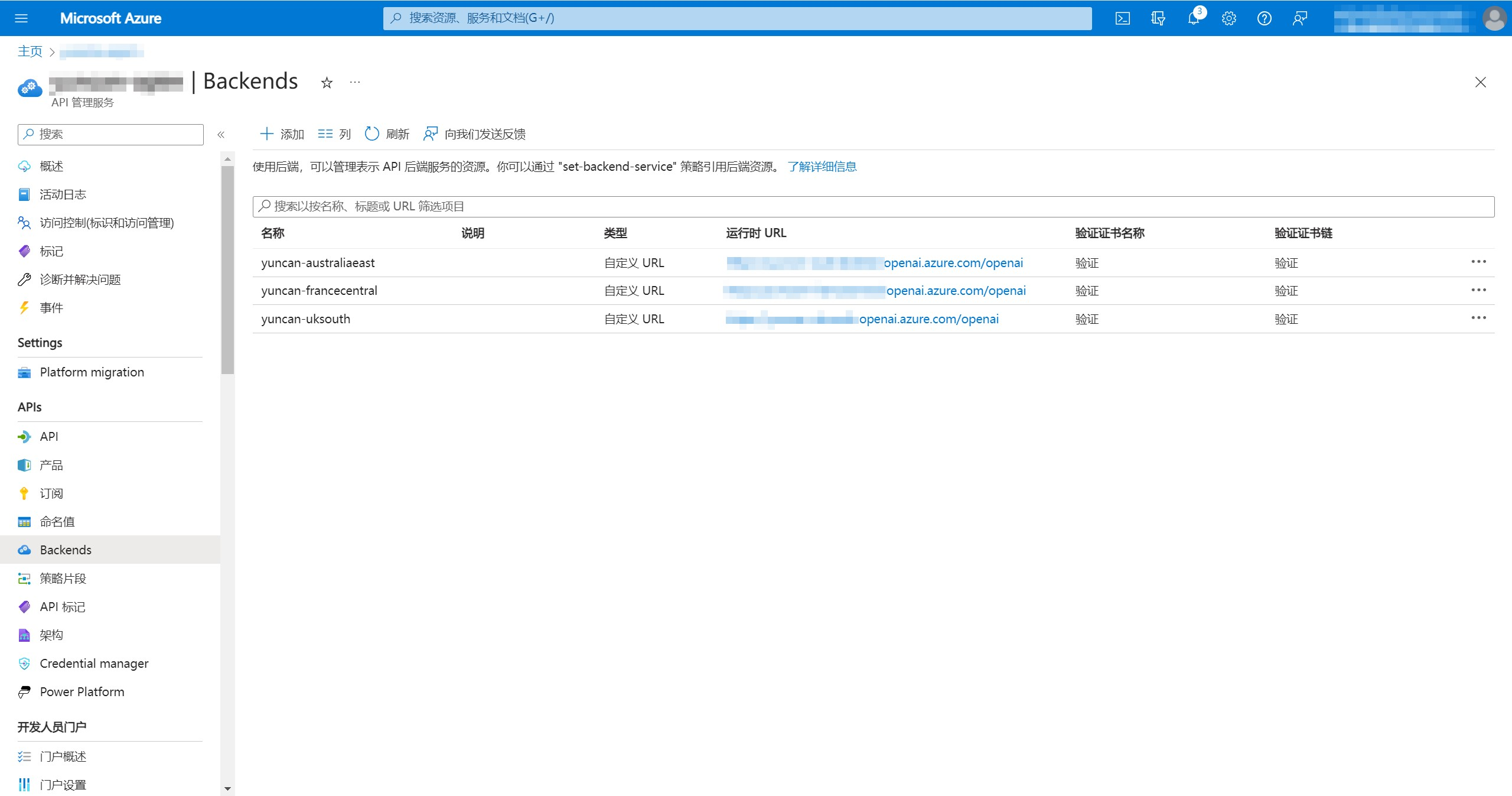
2、配置后端
点击左侧“Backends”进入后端配置界面,点击“添加”按钮添加后端为本次测试的三个资源。名称可以根据实际情况填写,我这里以资源所在地域命名。自定义URL填写资源终结点(endpoint)地址,后面加上/openai。在“头”中添加api-key=[Azure OpenAI密钥],我这里在左侧“命名值”中设置了密钥的变量名为yuncan-australiaeast,所以不直接显示密钥。
其他两个资源也按上述步骤进行后端添加,最后可以看到有三个后端在Backends中。
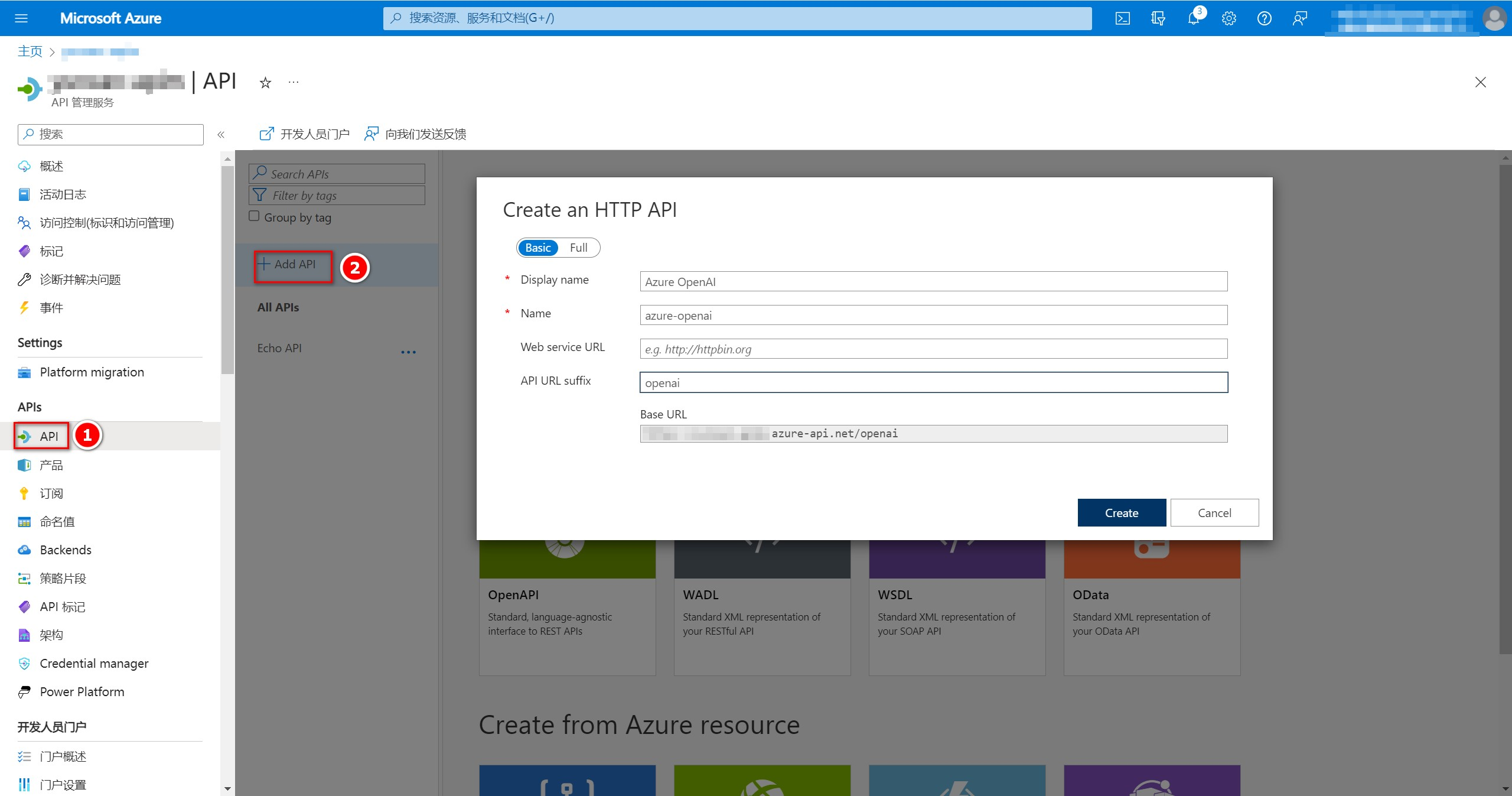
3、创建API
点击左侧“API”进入API设置界面,点击“Add API”创建一个HTTP API。名称自定义,我这里设置的”Azure OpenAI“,在“API URL suffix”中输入openai。
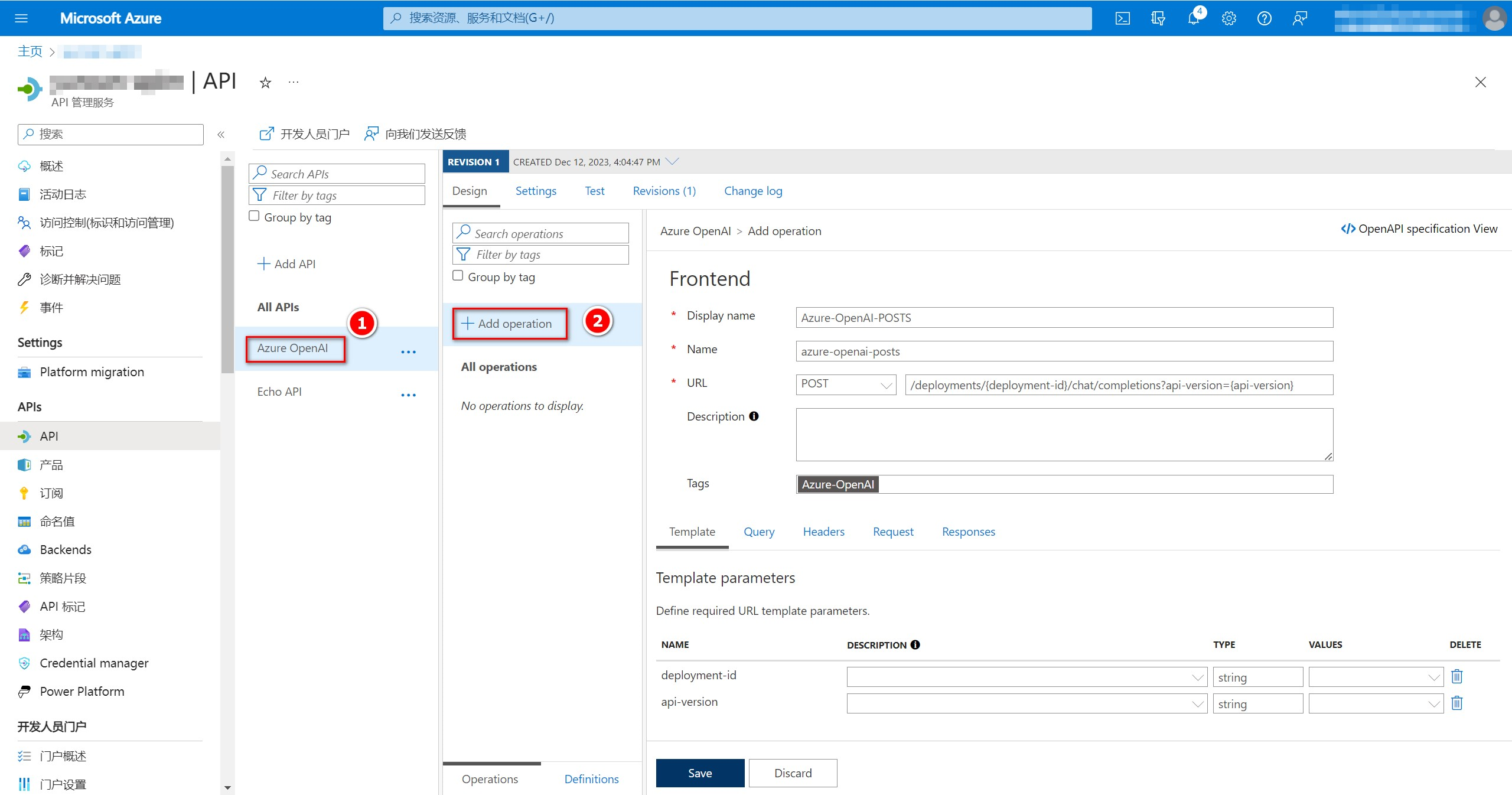
选中刚刚添加的”Azure OpenAI“,再点击”Add operation“添加一个操作。名称可以自定义,我这里设置”Azure-OpenAI-POSTS“,URL类型选择POST,URL地址填写/deployments/{deployment-id}/chat/completions?api-version={api-version},我这里设置Tags值为”Azure-OpenAI“,之后点击”Save“完成添加操作。
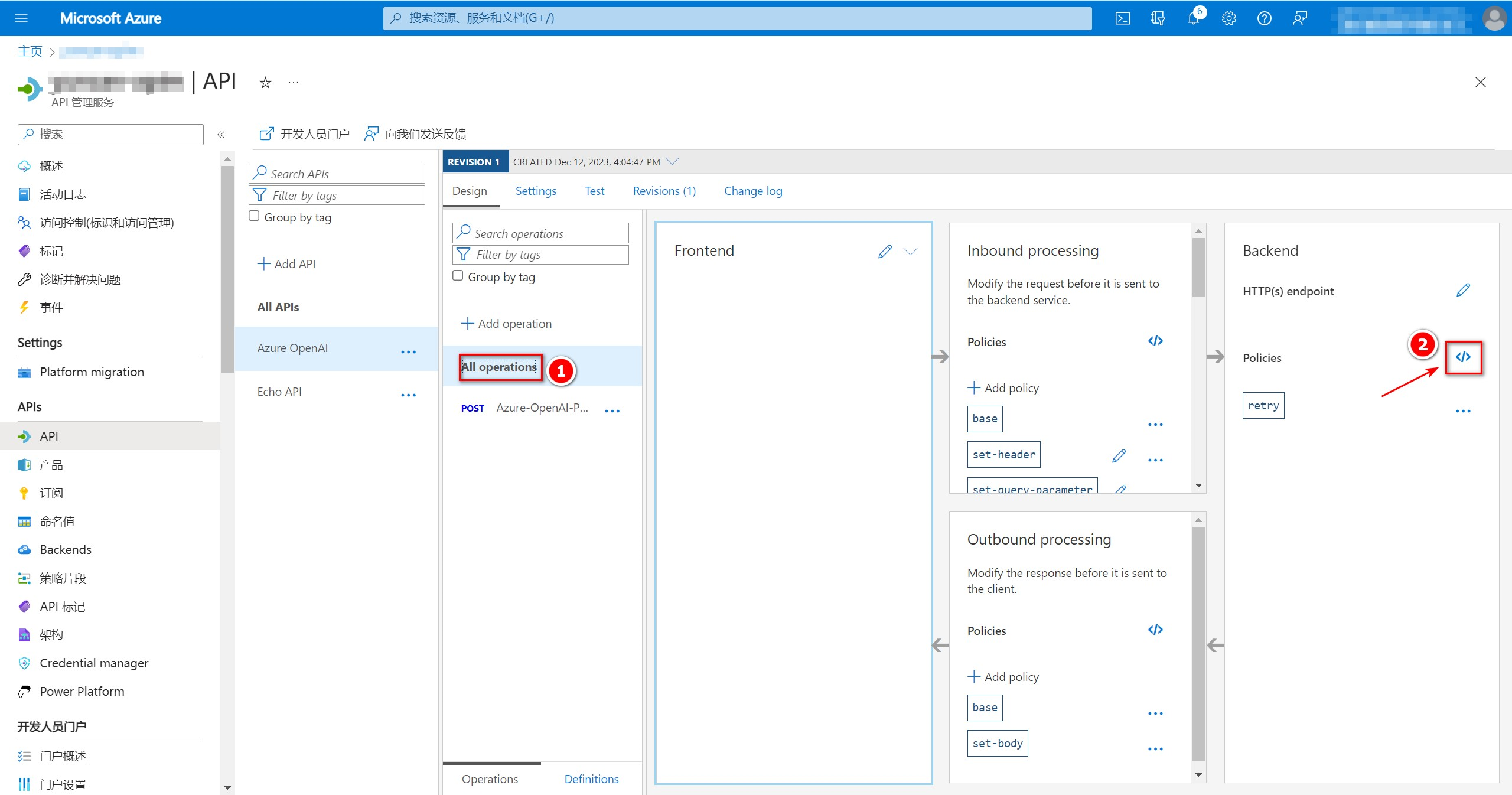
4、配置API策略
配置API策略来控制如何请求后端不同资源,本次示例API策略配置为轮询后端资源以达到负载均衡效果,解决TPM限制问题。以下设置仅作为参考:
依次点击”All Operations“-”Policies“旁边的”</>“配置API策略。
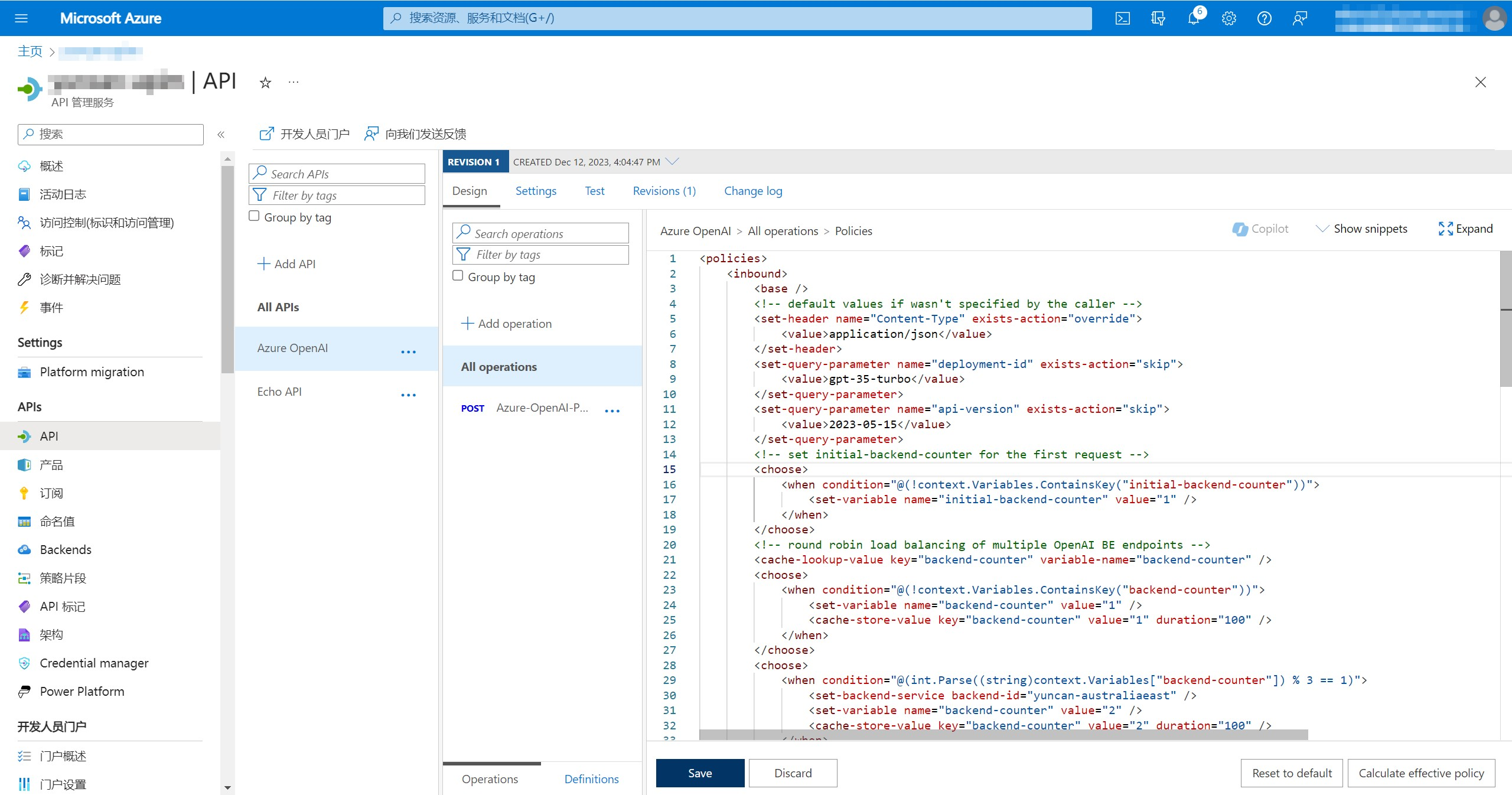
API策略示例(XML):
<policies>
<inbound>
<base />
<!-- default values if wasn't specified by the caller -->
<set-header name="Content-Type" exists-action="override">
<value>application/json</value>
</set-header>
<set-query-parameter name="deployment-id" exists-action="skip">
<value>gpt-35-turbo</value>
</set-query-parameter>
<set-query-parameter name="api-version" exists-action="skip">
<value>2023-05-15</value>
</set-query-parameter>
<!-- round robin load balancing of multiple Azure OpenAI BE endpoints -->
<cache-lookup-value key="backend-counter" variable-name="backend-counter" />
<choose>
<when condition="@(!context.Variables.ContainsKey("backend-counter"))">
<set-variable name="backend-counter" value="1" />
<cache-store-value key="backend-counter" value="1" duration="100" />
</when>
</choose>
<choose>
<when condition="@(int.Parse((string)context.Variables["backend-counter"]) % 3 == 1)">
<set-backend-service backend-id="yuncan-australiaeast" />
<set-variable name="backend-counter" value="2" />
<cache-store-value key="backend-counter" value="2" duration="100" />
</when>
<when condition="@(int.Parse((string)context.Variables["backend-counter"]) % 3 == 2)">
<set-backend-service backend-id="yuncan-francecentral" />
<set-variable name="backend-counter" value="3" />
<cache-store-value key="backend-counter" value="3" duration="100" />
</when>
<otherwise>
<set-backend-service backend-id="yuncan-uksouth" />
<set-variable name="backend-counter" value="1" />
<cache-store-value key="backend-counter" value="1" duration="100" />
</otherwise>
</choose>
</inbound>
<backend>
<!-- if HTTP 4xx or 5xx occurs, failover to the next Azure OpenAI BE endpoint -->
<retry condition="@(context.Response.StatusCode >= 500 || context.Response.StatusCode >= 400)" count="10" interval="0" first-fast-retry="true">
<choose>
<when condition="@(context.Response.StatusCode >= 500 || context.Response.StatusCode >= 400)">
<choose>
<when condition="@(int.Parse((string)context.Variables["backend-counter"]) % 3 == 1)">
<set-backend-service backend-id="yuncan-australiaeast" />
<set-variable name="backend-counter" value="1" />
<cache-store-value key="backend-counter" value="1" duration="100" />
</when>
<when condition="@(int.Parse((string)context.Variables["backend-counter"]) % 3 == 2)">
<set-backend-service backend-id="yuncan-francecentral" />
<set-variable name="backend-counter" value="2" />
<cache-store-value key="backend-counter" value="2" duration="100" />
</when>
<otherwise>
<set-backend-service backend-id="yuncan-uksouth" />
<set-variable name="backend-counter" value="1" />
<cache-store-value key="backend-counter" value="1" duration="100" />
</otherwise>
</choose>
</when>
</choose>
<forward-request buffer-request-body="true" />
</retry>
</backend>
<outbound>
<base />
<set-body>@{
JObject body = context.Response.Body.As<JObject>();
body.Add(new JProperty("backend-counter", ((string)context.Variables["backend-counter"])));
return body.ToString();
}</set-body>
</outbound>
<on-error>
<base />
</on-error>
</policies>API策略解释说明:
这是一个Azure API Management中的入口、后端和出口策略的XML配置。这个配置主要用于处理请求的流程,负载均衡请求到不同的后端服务,同时具备一些容错和重试机制。以下是该配置的主要功能解释: 【入口策略(Inbound)】 设置默认的请求头(Content-Type:application/json)和查询参数(deployment-id:gpt-35-turbo,api-version:2023-05-15)。 执行循环负载均衡,将请求分发到不同的后端服务,这里有三个后端服务(yuncan-australiaeast,yuncan-francecentral,yuncan-uksouth)。 通过缓存机制存储和获取backend-counter变量,以确保请求轮询到不同的后端服务。 【后端策略(Backend)】 在后端出现HTTP 4xx或5xx错误时,进行最多10次的重试。如果连续10次都失败,则将请求失败传递给客户端。 在重试过程中,根据backend-counter的值选择下一个后端服务。这样,即使某个后端服务不可用,请求也会被路由到其他可用的后端服务。 在多次请求的情况下,这个策略会使请求轮流分配到三个不同的后端服务,以实现负载均衡。如果某个后端服务不可用,会进行重试,并且在重试过程中,会切换到其他可用的后端服务。
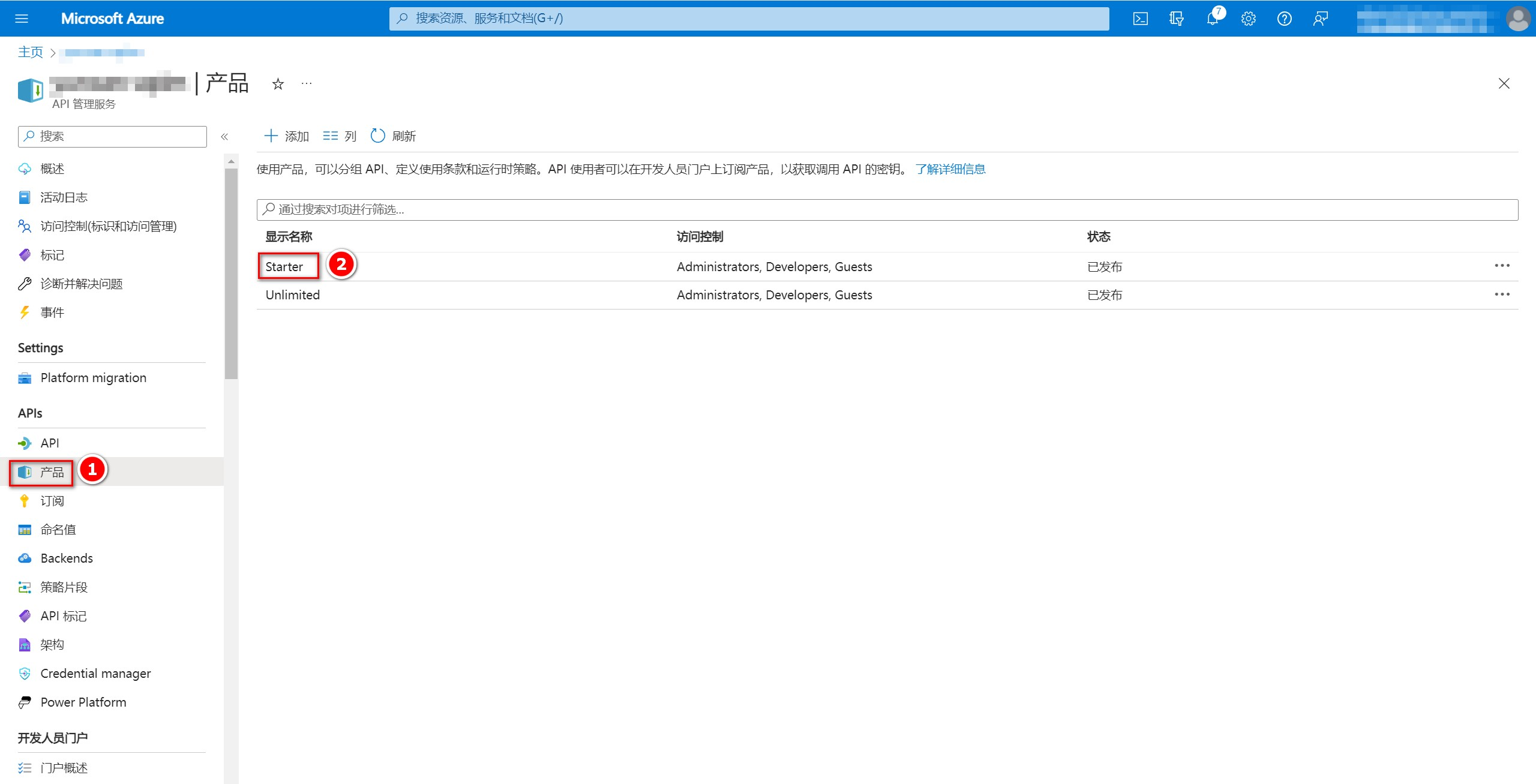
5、获取/创建APIM产品和订阅
如果应用要通过APIM的网关URL来调用API,还需要密钥,这个密钥需要在APIM产品中获取。操作如下:
在APIM控制台点击右侧的”产品“,根据需要添加产品(APIM 默认有Starter和Unlimited产品),这里我添加至Starter产品中。
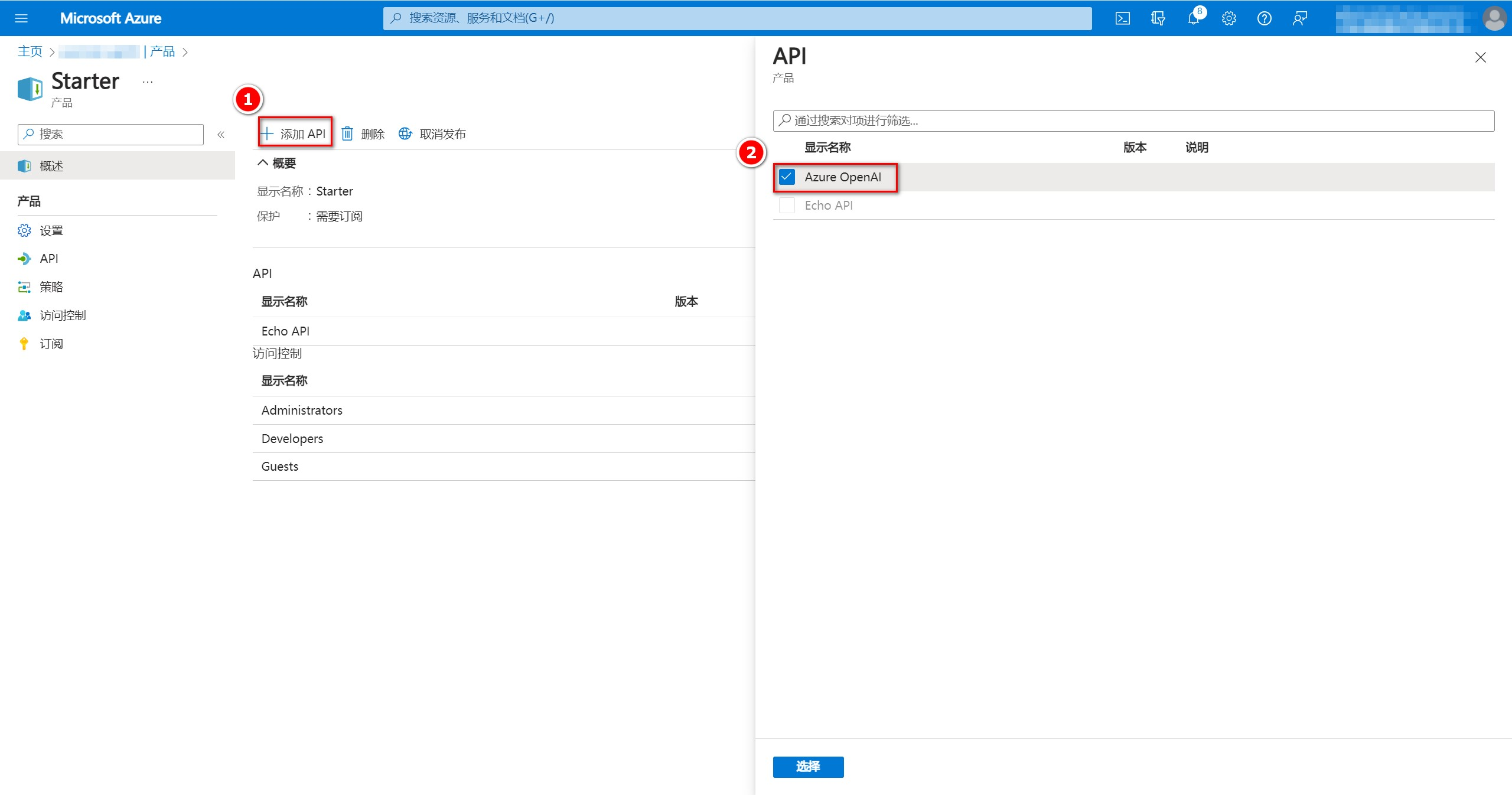
点击”添加API“,然后选择我们刚刚在API中添加的”Azure OpenAI“,点击”选择“,之后我们便可以在左侧产品的”API“中看到添加的”Azure OpenAI“。
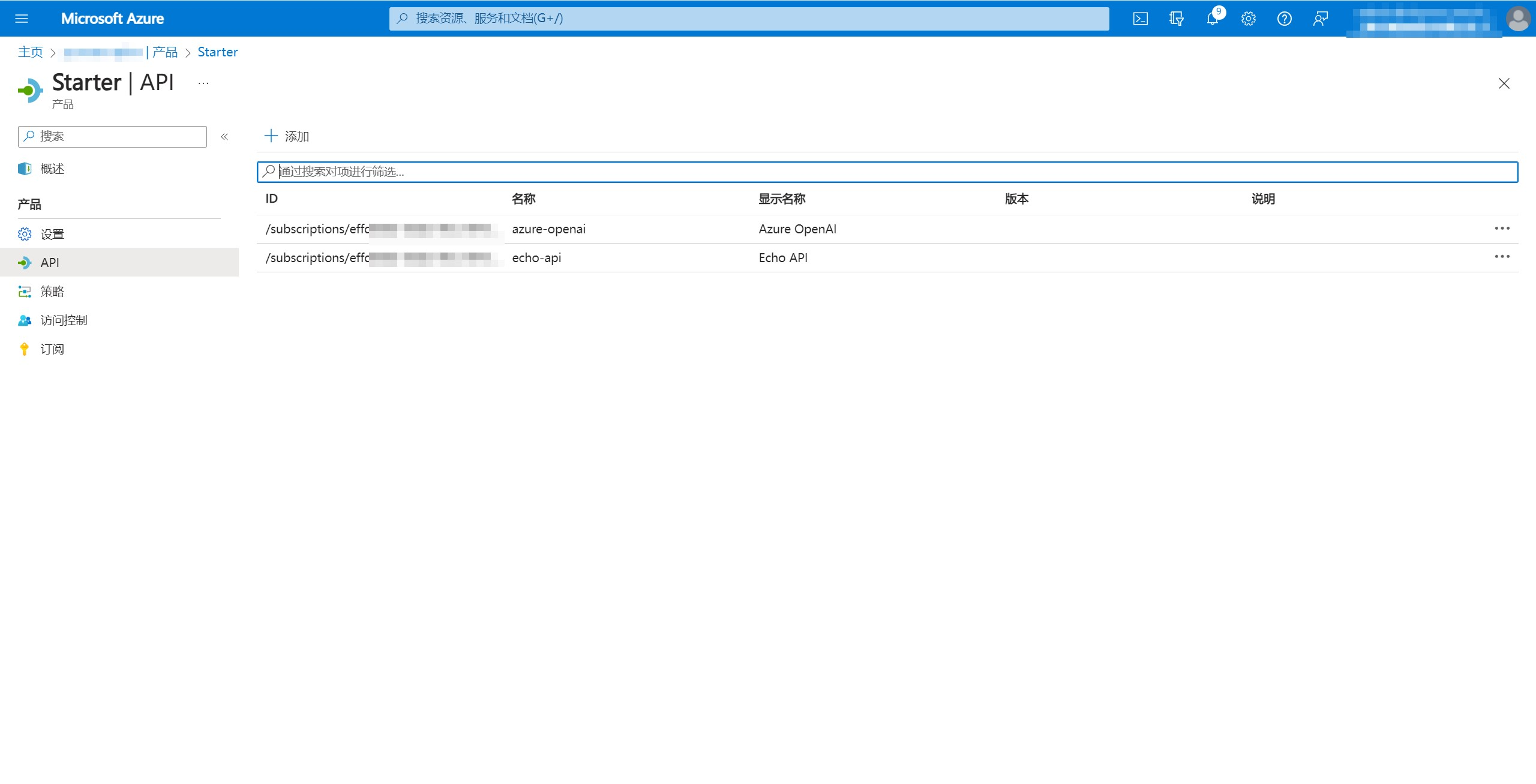
返回APIM控制台,点击左侧”订阅“,获取”范围“为”产品: Starter“的密钥。
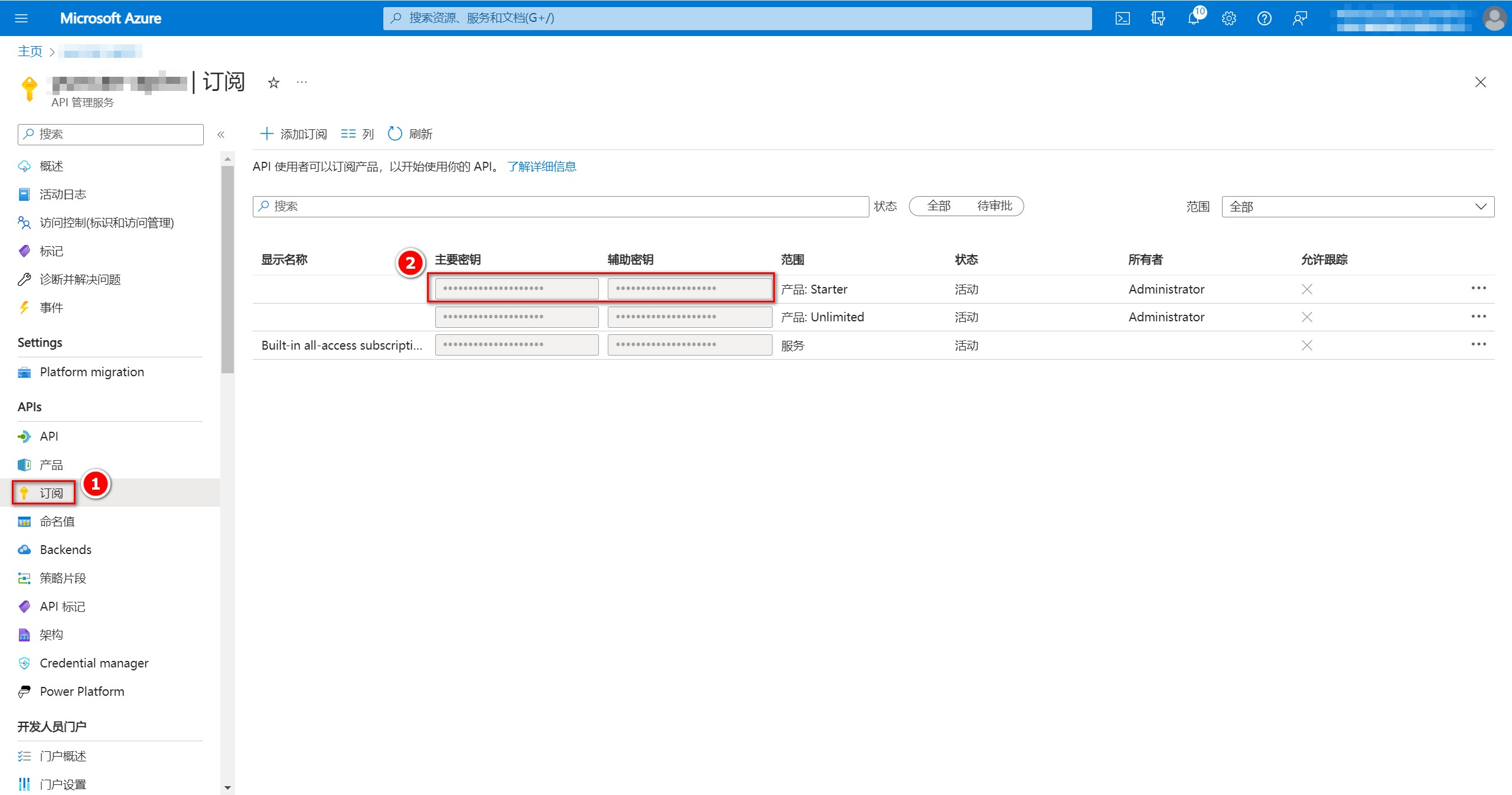
也可以添加一个新的订阅,范围选择”产品“,产品选择”Starter“。
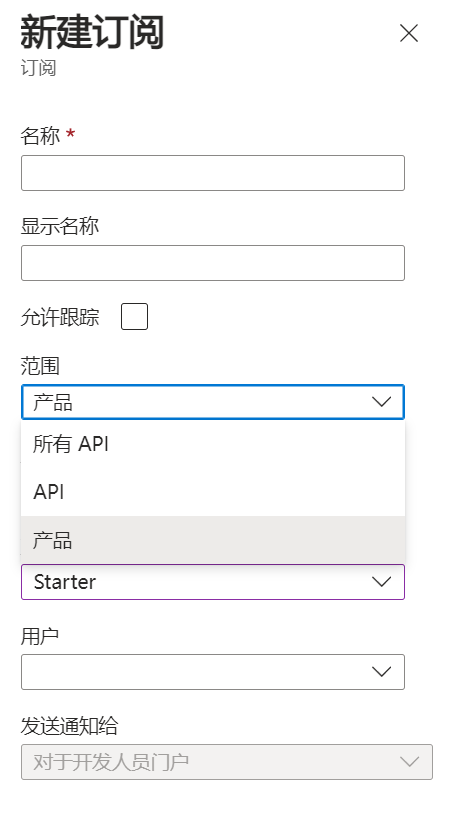
6、测试API
利用API工具提交POST请求,多次调用API并检查backend-counter,如果该值一直在变化,则说明配置成功了,目前每次API请求APIM都是轮询后端三个资源,从而避免TPM相关限制问题。虽然新的模型有了更高的TPM选项,但是这也不失作为一种应对限制时的办法。
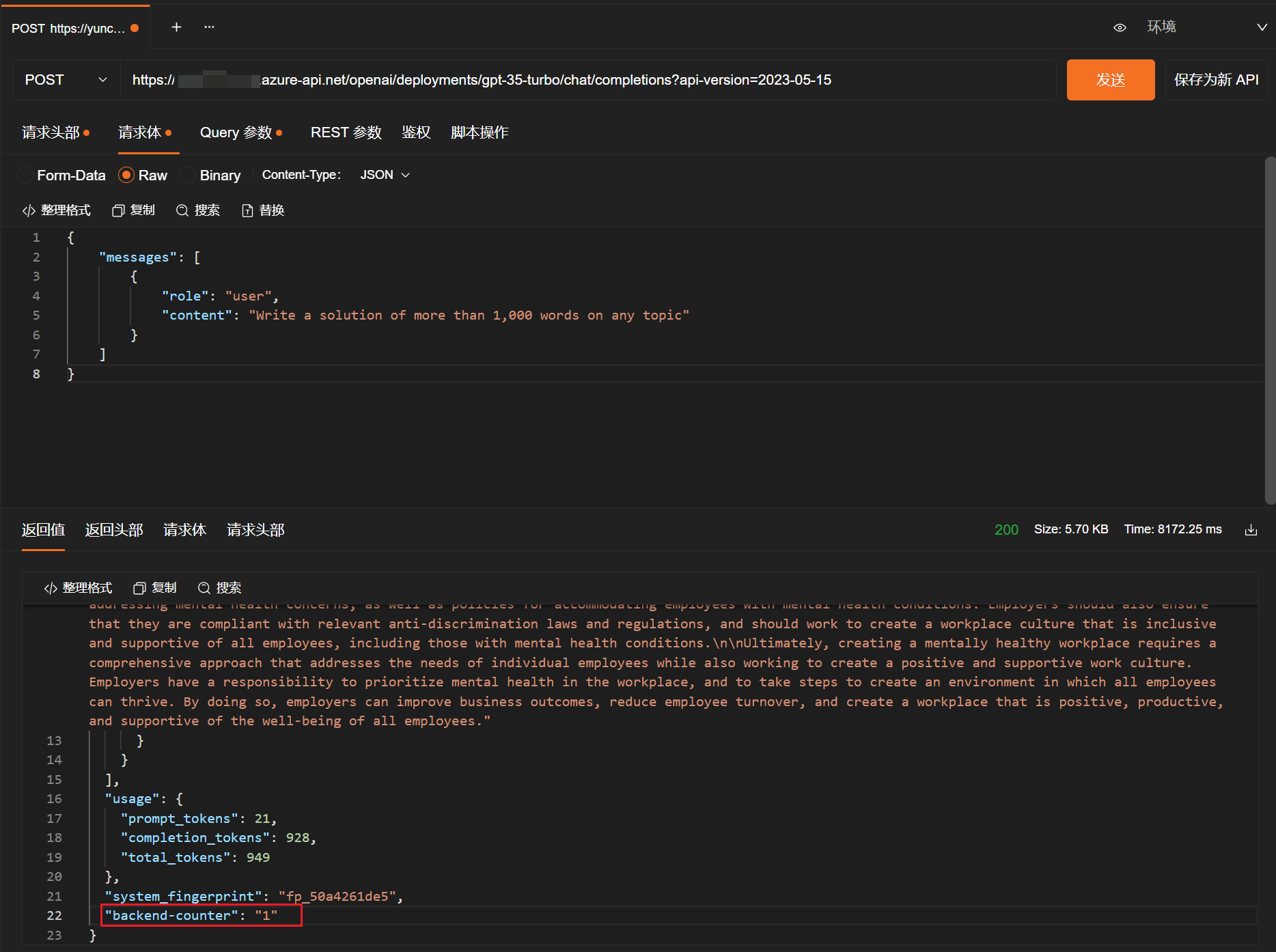
多次发起请求,观察backend-counter值,如果该值一直在变化,则说明配置成功,负载均衡轮询生效了。
